
 返回学校首页
返回学校首页
 研究进展
研究进展
张玉清/李煜东:CSL-大规模中文科学文献数据集【COLING,2022】
2022-09-22 发布:[信息工程学院] 点击:747次
随着科学文献出版数量的增加,NLP 工具在科学文献写作、检索和归档上都起到愈发重要的作用。例如,之前的一些研究围绕引用推荐、学科分类、自动摘要,以及学术预训练语言模型等方面展开。除此之外,科学文献作为一种高质量的规范文本,也为许多NLP任务提供了天然有标注数据。此前的研究者基于预发表平台或科学文献检索平台总结了一系列科学文献相关的数据集,包括论文全文,引用图谱等等类型。然而,这些工作主要基于英文,在中文领域,目前还没有公开的科学文献数据资源和对应的 NLP 下游任务,这在一定程度上限制了中文自然语言处理的发展。
为了填补这一空白,我院教师张玉清副教授和硕士李煜东等提出了CSL-大规模中文科学文献数据集,包含约 40 万篇中文论文的元数据(标题、摘要、关键词以及学科领域标签)。此外,为了推动中文科学文献测评任务,该研究设计了4个下游任务以及对应的基准测评。本文的主要贡献如下:
1、整理和公开首个中文科学文献数据集,可以被用于语言模型预训练或者学术相关NLP下游任务;
2、基于CSL,提供了科学文献基准测评,用于测试语言模型处理科学文献时的性能;
3、实现了一系列端到端语言模型作为极限模型,实验结果展示了目前的NLP模型对于中文科学文献处理的主要难点。
该研究提出CSL作为中文数据集的重要补充,填补了中文数据在科学文献领域的空白。该研究还探索了天然有标注数据构建同源任务,预训练语言模型在多任务学习时的性能,为之后的研究提供参考。同时,CSL的数据分布具有天然的跨任务-小样本特性,可以用于小样本学习测评,为元学习、小样本学习提供数据资源。
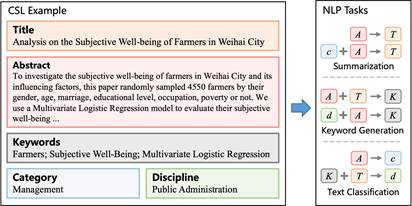
图1:CSL数据样例及衍生任务
该研究数据源自 国家科技资源共享服务工程技术研究中心,根据《中文核心期刊目录》进行筛选并标注领域标签。具体来说,为《中文核心期刊目录》中的每个期刊标注所属学科领域,并只保留专注于单一学科的期刊。因此,可以根据论文发表所在的期刊,得到论文的学科和门类标签。CSL 数据集收集自广泛的中文学术期刊,根据期刊的领域分成了 13 个一级门类标签(例如理科、工科)和 67 个二级学科标签(例如计算机科学与技术、电子信息)。数据分布如表-1所示:
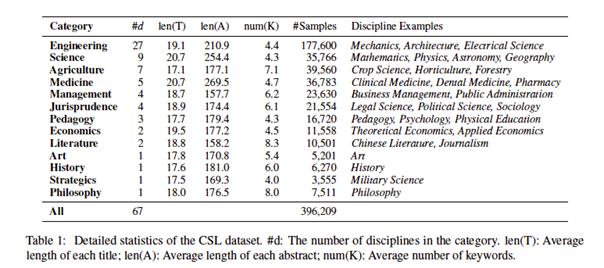
表1:CSL数据分布
与相关工作相比,CSL具有如下优势:1. 更广的领域分布。已有的科学文献数据集通常针对某个或某些领域,而CSL几乎包含所有中文研究领域,并且具有更细粒度的标注。2. 新的数据源。已有的资源从一些特定的英文数据源中收集,并且有一定重复。CSL源自中文核心期刊,对现有数据源产生互补。3. 更高的质量和准确性。现有的数据源例如预发表平台的一些论文没有经过同行评审,而CSL源自中文核心期刊的已发表论文,因此具有更高的准确率和文章质量。对比如表-2所示:

表2:CSL与同类资源对比
学术论文的元数据包含丰富的语义信息,使它成为一种天然有标注数据。预测这些信息之间的相互关系可以构成许多 NLP 任务,例如用论文摘要预测标题可以视为一个文本摘要任务;用论文标题预测所属领域则是文本分类任务。这样的组合可以有很多种,因此可以构成了一系列下游任务。为了推动中文科学文献NLP的发展,本文构建了4个常见任务作为基准测评,包括文本摘要、关键词生成、论文学科分类和论文门类分类。
实验测试了常见的语言模型例如BART、T5和Pegasus在测评任务上的表现。实验结果表3所示:

表3:实验结果
根据结果分析,T5在多任务学习的性能显著优于其他模型。然而,这还不能满足现实场景的需要,未来需要针对科学文献处理研究专用模型。此外,在CSL语料上进行增量预训练可以进一步提升模型性能,这展示了CSL作为预训练语料的有效性。
上述研究成果发表在自然语言处理领域的国际顶级会议COLING 2022(International Conference on Computational Linguistics 2022)上。
全文链接:https://arxiv.org/abs/2209.05034

校址:北京市海淀区学院路29号 邮编:100083
版权所有中国地质大学(北京) 文保网安备案:1101080023

校址:北京市海淀区学院路29号
邮编:100083
技术支持:信息网络与数据中心
@版权所有:中国地质大学(北京)
文保网安备案:1101080023

